

Edge Computing es una arquitectura de tecnología de la información distribuida en la que los datos del cliente se procesan en la periferia de la red, lo más cerca posible de la fuente de origen.
Los datos son el elemento vital de los negocios modernos, ya que brindan información comercial valiosa y respaldan el control en tiempo real de los procesos y operaciones comerciales críticos. Las empresas de hoy están inundadas en un océano de datos, y se pueden recopilar grandes cantidades de datos de forma rutinaria desde sensores y dispositivos IoT que operan en tiempo real desde ubicaciones remotas y entornos operativos inhóspitos en casi cualquier parte del mundo.
Pero esta avalancha virtual de datos también está cambiando la forma en que las empresas manejan la informática. El paradigma de computación tradicional basado en un centro de datos centralizado e Internet no es adecuado para mover grandes cantidades de datos del mundo real que crecen sin cesar. Las limitaciones de ancho de banda, los problemas de latencia y las interrupciones impredecibles de la red pueden resultar un perjuicio para dichos esfuerzos. Las empresas están respondiendo a estos desafíos de datos mediante el uso de la arquitectura Edge Computing.
La informática perimetral mueve una parte de los recursos informáticos y de almacenamiento fuera del centro de datos central
En lugar de transmitir datos sin procesar a un centro de datos central para su procesamiento y análisis, ese trabajo se realiza donde realmente se generan los datos, ya sea una tienda minorista, una planta de producción, una empresa de servicios públicos en expansión o en una ciudad inteligente. Solo el resultado de ese trabajo informático en el borde, como información comercial en tiempo real, predicciones de mantenimiento de equipos u otras respuestas procesables, se envía de vuelta al centro de datos principal para su revisión y otras interacciones humanas.
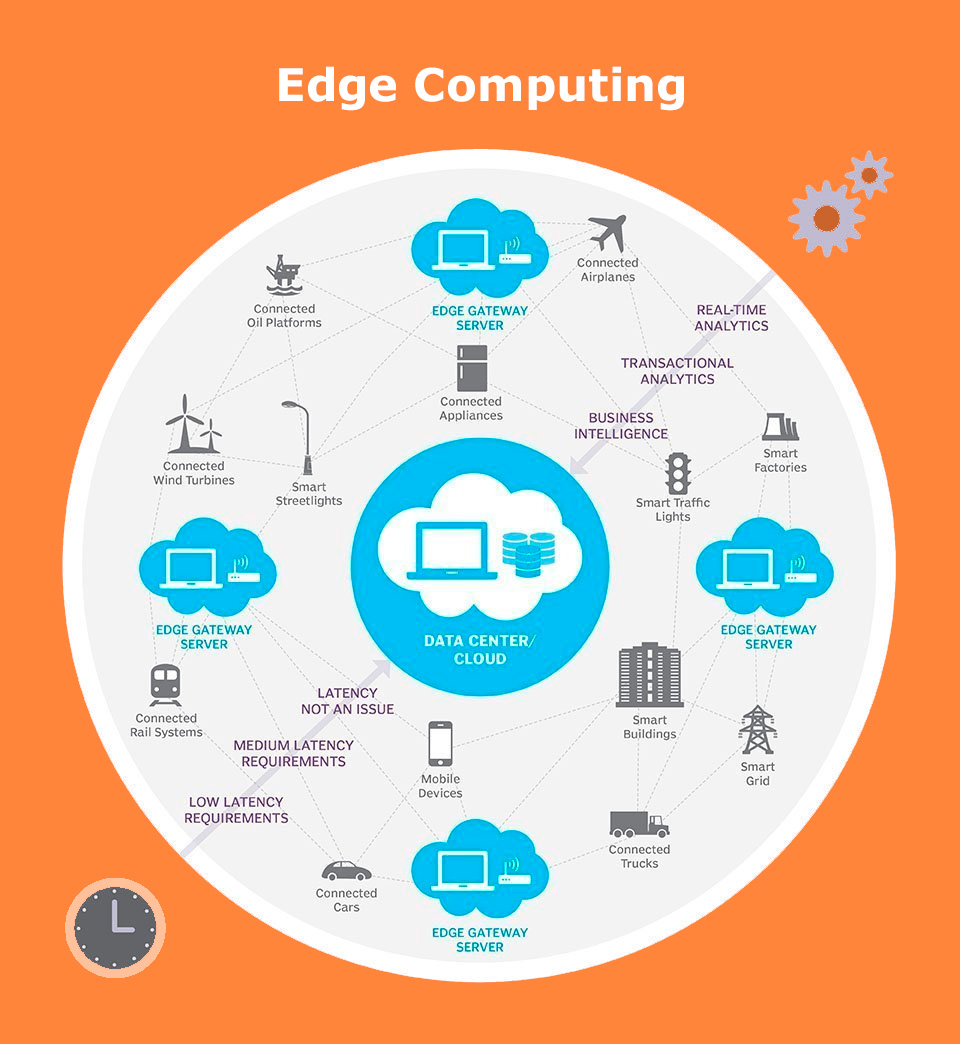
¿Cómo funciona Edge Computing?
Edge computing es todo una cuestión de ubicación. En la informática empresarial tradicional, los datos se producen en un punto final del cliente, como la computadora de un usuario. Esos datos se mueven a través de una WAN como Internet, a través de la LAN corporativa, donde una aplicación empresarial almacena y trabaja con los datos. Los resultados de ese trabajo se transmiten luego al terminal del cliente. Este sigue siendo un enfoque probado y probado en el tiempo para la computación cliente-servidor para la mayoría de las aplicaciones comerciales típicas.o.
Pero la cantidad de dispositivos conectados a Internet y el volumen de datos producidos por esos dispositivos y utilizados por las empresas está creciendo demasiado rápido para que las infraestructuras de centros de datos tradicionales lo acomoden. La perspectiva de mover tantos datos en situaciones que a menudo pueden ser sensibles al tiempo o a las interrupciones ejerce una presión increíble sobre Internet global, que a menudo está sujeto a congestión e interrupciones.
Por lo tanto, los arquitectos de TI han cambiado el enfoque del centro de datos central al borde lógico de la infraestructura, tomando los recursos informáticos y de almacenamiento del centro de datos y moviéndolos al punto donde se generan los datos. El principio es sencillo: si no puede acercar los datos al centro de datos, acerque el centro de datos a los datos. El concepto de computación perimetral no es nuevo y tiene sus raíces en ideas de computación remota que datan de hace décadas, como oficinas remotas y sucursales, donde era más confiable y eficiente ubicar los recursos informáticos en la ubicación deseada en lugar de confiar en una única ubicación central.